论文复现 - MAGIS
MAGIS
PKU ASPLOS'24MAGIS 主要涉及计算图优化和转换,并实现内存削峰。
Setup
主要软件包版本。基于以下环境运行了 Resnet50 进行验证。
- CUDA 11.6
- CuDNN 8.4.0
- PyTorch 1.13.1
- Python 3.10.5
实验说明
根据 Renze Chen 描述,实验主要是跑一遍 forward + backward,测时间和内存开销。Samples 输出的 results.csv 里有实验一节里的各种评估指标。
至于数据集,并不重要,毕竟是 sys 工作,主要侧重性能,数据随机生成即可。
负载
实现了 ResNet,ViT, Bert 等常见负载。另实现两个大模型负载以增强结论。
torch_cuda.py
接口模块,相当于把 nn/ 中定义的负载网络转为 pytorch 计算图,然后再接入 MAGIS 工作流。待研读代码。
运行实验
笔者的实验条件实在匮乏,将 nn.Bert() 默认参数做了修改,可惜仍然 OOM。最后进一步降 batch_size 为 16,算是跑起来了。MAGIS 尚有一些模块没有实现,可以理解,只是运行时会报一些参数上的错误
1 | TypeError: OpGraph.conv2d() takes from 3 to 7 positional arguments but 8 were given |
这里有输出就不用管,简单忽略即可。另有一些数据类型上的问题:
1 | RuntimeError: expected scalar type Float but found BFloat16(Half) |
按照原文改成 torch.bfloat16 或 float16 都稳定复现此问题,推测是 torch 1.13 的锅。暂时按 float32 运行,不出意外地再次 OOM 了。用 float32, 降至 batch_size = 8 仍无法运行,暂时搁置。
Result
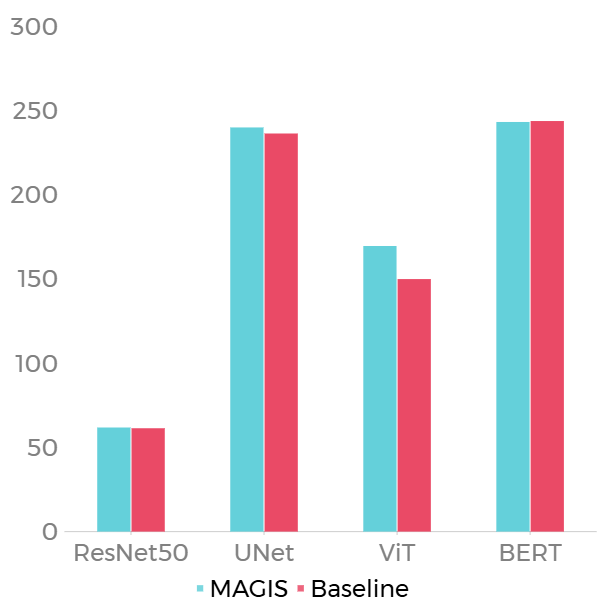
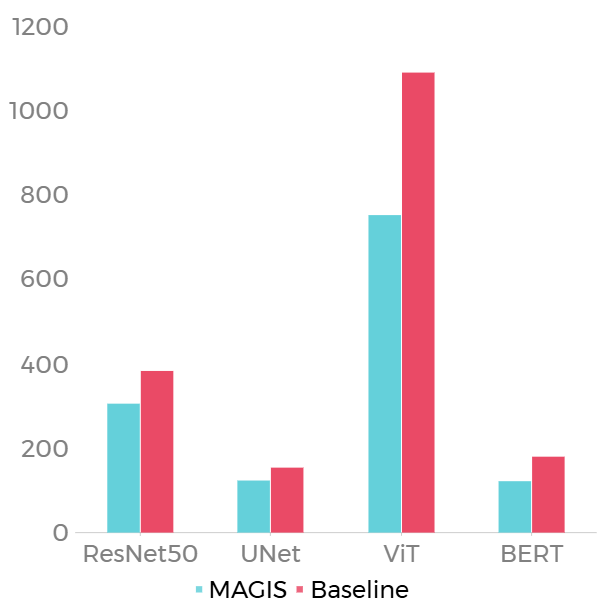
测试了 ResNet50、UNet、ViT、BERT 四个负载,结果如下。
| name | device memory limit | latency limit | memory limit | latency limit ratio | memory limit ratio | weight memory | opt-is-prof-result | opt-latency | opt-memory | opt-simul-latency | opt-simul-memory | ori-is-prof-result | ori-latency | ori-memory | ori-simul-latency | ori-simul-memory |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | 3157573632 | None | 307137126.4 | None | 0.8 | 25502912 | TRUE | 61.81041336 | 306195712 | 98.23434734 | 378773952 | TRUE | 61.37547684 | 383921408 | 64.40793696 | 455844288 |
| UNet | 3157573632 | None | 1234749030 | None | 0.8 | 31372994 | TRUE | 239.9398092 | 1237252096 | 219.9666572 | 1163835074 | TRUE | 236.343043 | 1543436288 | 202.1358391 | 1470019266 |
| ViT | 3157573632 | None | 872511897.6 | None | 0.8 | 85702656 | TRUE | 169.5556183 | 751625984 | 140.1534884 | 856602880 | TRUE | 149.9205729 | 1090639872 | 136.0365616 | 1243764736 |
| BERT | 3157573632 | None | 1442303181 | None | 0.8 | 84934656 | TRUE | 243.1806081 | 1220583424 | 226.0288952 | 1337982976 | TRUE | 243.7401377 | 1802878976 | 216.6313542 | 1953890304 |
| Latency | Peak Memory Usage |
|---|---|
 |
 |
Baseline: 与 PyTorch 动态计算图 (Eager Mode) 对比。
实验结果分析如下。
- Latency: 平均 Latency 降低 3.39%,在三个 Benchmarks 上取得了加速,在 BERT 上有 0.23% 的时延增加。
- Peak Memory Usage: 平均降低 25.85% 的峰值内存,在 ViT 和 BERT 明显,分别优化 31.05% 和 32.28%。由实验结果知,MAGIS 的优化策略对 Transformer 十分有效。
以上结果基本说明 MAGIS 的有效性。
附 | 环境配置
点击直达本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Miya's Blog!

评论


